Title here
Summary here
Before you can execute a data flow, you need to link your sources, transformations and destinations. The linking is quite easy - every source component and every transformation offers a LinkTo() method. This method accepts a link target, which either is another transformation or a destination.
Let’s start with an example of Linking a CsvSource to a RowTransformation and then to a MemoryDestination.
//Create the components
CsvSource source = new CsvSource("text.csv");
RowTransformation rowTrans = new RowTransformation( row => row );
MemoryDestination dest = new MemoryDestination();
//Link the components
source.LinkTo(row);
row.LinkTo(dest);This will result in a flow which looks like this:
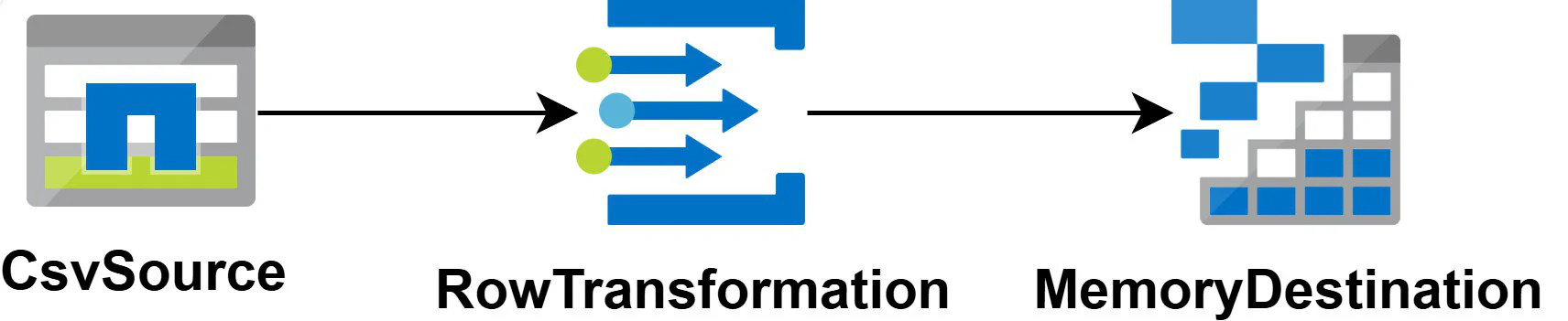
Our source file would could look like this:
Id,Value
0,-
1,A
2,B
-1,CNow you can already write this flow with less code. There is a fluid notation available, which give you the same result:
//Link the components
source.LinkTo(row).LinkTo(dest);This notation can be used most of the time - please note that it won’t work with Multicast or MergeJoin as these
components have more than one input respective output.
If your transformation has a different output type than your input, you need to adjust the linking a little bit. The LinkTo
accepts a type that defines the output of the linking.
E.g. if you have a RowTransformation<ExpandObject, OutputType> row, the linking would look like this:
source.LinkTo<OutputType>(row).LinkTo(dest)Whenever you link components in a data flow, you can add a filter expression to the link - this is called a predicate for the link. The filter expression is evaluated for every row that goes through the link itself. If the evaluated expression is true, data will pass into the linked component. If evaluated to false, the data flow will try the next link to send its data through.
This example code will split up the data from the source and send it into three different destinations, dependening on their Value:
public class MyRow {
public int Id { get; set; }
public string Value { get; set; }
}
CsvSource<MyRow> source = new CsvSource<MyRow>("test.csv");
MemoryDestination<MyRow> dest1 = new MemoryDestination<MyRow>();
MemoryDestination<MyRow> dest2 = new MemoryDestination<MyRow>();
MemoryDestination<MyRow> dest3 = new MemoryDestination<MyRow>();
source.LinkTo(dest1, row => row.Value == "A");
source.LinkTo(dest2, row => row.Value == "B");
source.LinkTo(dest3, row => row.Value != "A" && row.Value != "B");Data will be send only into one of the connected links. If there is more than one link, the first link that either has no predicate or which predicate returns true is used. If you want to duplicate your data, consider to add a Multicast into your flow.
Note
Whenever you use predicates, sometime you end up with data which you don’t want to write into a destination. Unfortunately, your DataFlow won’t finish until all rows where written into any destination block. That’s why there is a VoidDestination in ETLBox. Use this destination for all records for that you don’t wish any further processing.
CsvSource<MyRow> source = new CsvSoure<MyRow>("test.txt");
VoidDestination<MyRow> voidDest = new VoidDestination<MyRow>();
source.LinkTo(dest, row => row.Id > 0);
souce.Link(voidDest, row => row.Id <= 0);In this exmple above we have a dataflow where we keep only rows from the source that have an Id greater than. Records with an Id below 0 are ignored.
You don’t have to define the VoidDestinatin explicitly. There is a shorter way for the example above:
source.LinkTo(dest, row => row.Id > 0, row => row.Id <= 0);Internally, this will create a VoidDestination when linking the components, so both example codes will behave exactly the same.
By default, exceptions in user code will be left unhandled in all data flow components. Whenever your code throws an exception within a source, transformation or
destination, this exception will bubble up in your component and set the completion state of your component to Faulted.
Consider the following code
CsvSource<MyRow> source = new CsvSource<MyRow>("test.csv");
RowTransformation<MyRow> row = new RowTransformation<MyRow>();
row.TransformationFunc = row => {
if (row.Id <= 0)
throw new ArgumentException("Id must have a value > 0!");
else
return row;
};
MemoryDestination<MyRow> dest = new MemoryDestination<MyRow>();
source.LinkTo(row);
row.LinkTo(dest);
Network.Execute(source); //<-- the exception will be rethrown here!As you can see, with our test data defined at the beginning (where we have Id values less than 0) our flow will throw an exception during execution. When you run Network.Execute(..), data will be send through the flow and the exception will be thrown in the RowTransformation. When an exception is encountered, the execution of all components ih the flow is canceled or faulted. All components in the flow that are located in the network before the exception source are cancelled. All other components will be faulted, and contain the exception of the component that throws the exception.
As all data flow are executed asynchrounously, the exception is wrapped in an AggregateException. In order to unwrap the original exception, you could rethrow the InnerException:
try {
Network.Execute(source);
}
catch (AggregateException ae) {
throw ae.InnerException;
}Sometimes, if multiple exceptions happen simultanously, the AggregateExcpetion can hold more than one Exception. The InnerExceptions collection will hold all exceptions that happened during execution.
Note
Exception - if a component throws an exception, a reference to this exception is stored here as well.One valid option to handle exceptions in your code is to catch (all) them with a normal try/catch block, so that no unhandled exception can occur.
The other option is to use the build-in error linking in ETLBox. If you want to handle exceptions within your data flow, some components offer the ability to redirect errors.
Beside the normal LinkTo method, you can use the LinkErrorTo to redirect erroneous records into a separate pipeline.
Here is an example for a csv source, where all error records are send to CsvDestination:
CsvSource<MyRow> source = new CsvSource<MyRow>("test.csv");
RowTransformation<MyRow> row = new RowTransformation<MyRow>();
row.TransformationFunc = row => {
if (row.Id <= 0)
throw new ArgumentException("Id must have a value > 0!");
else
return row;
};
MemoryDestination<MyRow> destData = new MemoryDestination<MyRow>();
CsvDestination<ETLBoxError> errorDest = new CsvDestination<ETLBoxError>("error.csv");
source.LinkTo(row);
row.LinkTo(destData);
row.LinkErrorTo(errorDest);
Network.Execute(source); //No exception will be thrown!LinkErrorTo only accepts transformations or destinations that have the input type ETLBoxError. This class contains the exception itself, as well as an exception message, the time the error occurred, and the faulted record as json (if it was possible to convert it).
ETLBoxError is internally defined like this:
public class ETLBoxError
{
public string ErrorText { get; set; }
public DateTime ReportTime { get; set; }
public string ExceptionType { get; set; }
public string RecordAsJson { get; set; }
}When we run this code, no exception will be thrown. All exceptions will be redirected into the file error.csv.
This would be the content of the error file when running the example data flow above:
ErrorText,ReportTime,ExceptionType,RecordAsJson
Id must have a value > 0!,2021-03-26 14:41:26.952,System.ArgumentException,"{""Id"":0,""Value"":""-""}"
Id must have a value > 0!,2021-03-26 14:41:27.679,System.ArgumentException,"{""Id"":-1,""Value"":""C""}"There is no restriction how to link your data flow. You can link sources or transformation to as many components as you like. There are different possibilites to join, split or duplicate (broadcast) your data,
Consider the following possible Network that could be constructed with ETLBox components:
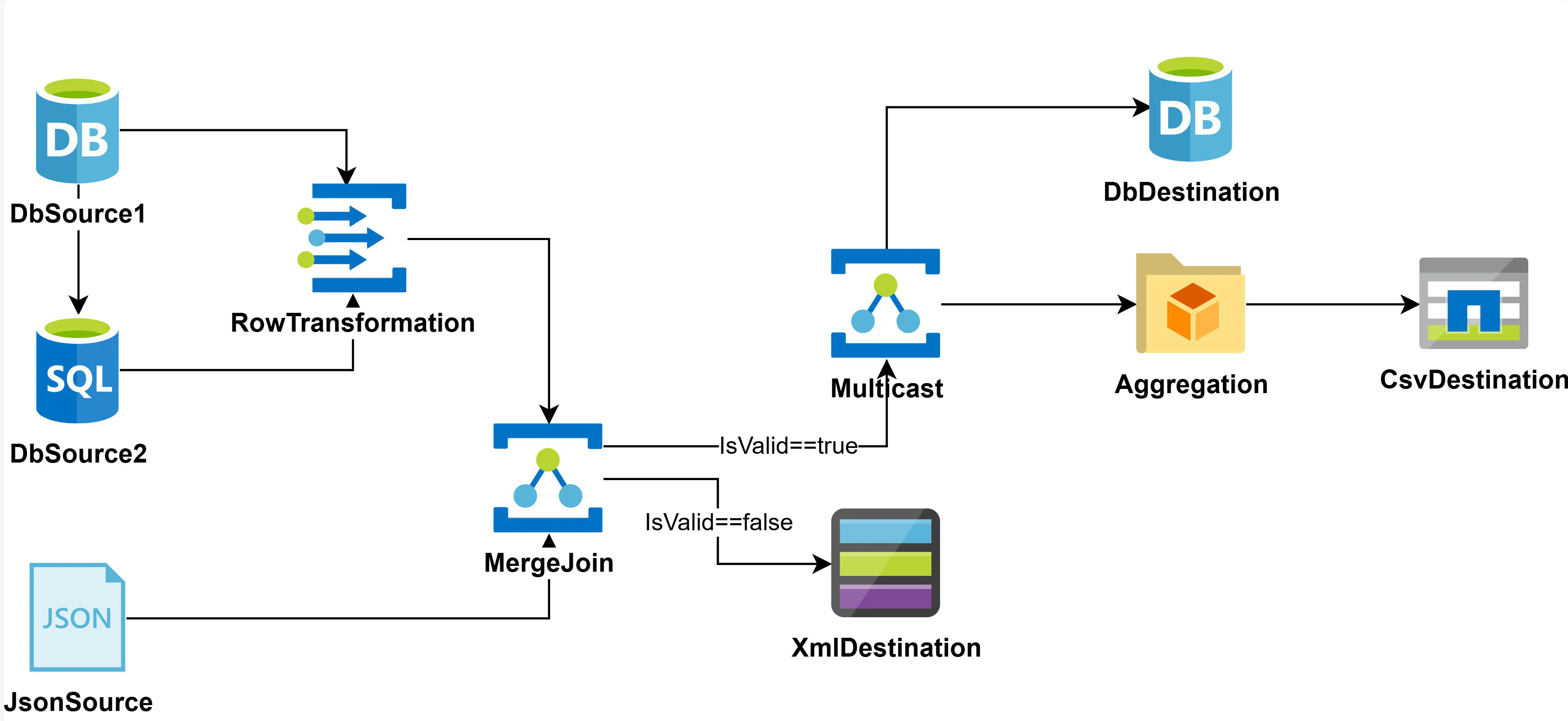
This is the corresponding code snipped (only showing the linking part):
dbSource1.LinkTo(rowTransformation);
dbSource2.LinkTo(rowTransformation);
rowTransformation.LinkTo(mergeJoin);
jsonSource.LinkTo(mergeJoin);
mergeJoin.LinkTo(multicast, row => row.IsValid == true);
mergeJoin.LinkTo(xmlDestination, row => row.IsValid == false);
multicast.LinkTo(dbDestination);
multicast.LinkTo(aggregation);
aggregation.LinkTo(csvDestination);This example demonstrates that it is possible to create complex networks with ETLBox.
Note
MergeJoin. For broadcasting (cloning) your data into multiple outputs, you can use the Multicast